Learn
|
Articles
|
Matilde Alves
|
26 October 2023
Solving the challenges of LLMOps
About the author
Anna Dollbo| Design & Implementation Engineer
Anna Dollbo works as a Design & Implementation Engineer at Deeploy, a platform focused on enabling responsible deployment and explainability of AI, particularly in high risk use cases. With an academic background in Cognitive Science and Artificial Intelligence, Anna focuses her research on human-centric AI-solutions, specifically using explainability and human feedback as a tool for more responsible AI deployments.
The rapid advancements in Foundational Models (FM), among them Large Language Models (LLMs), have captured the interest of many companies. They are exploring ways to leverage LLMs’ powerful natural language processing and generation capabilities with the ultimate objective of optimizing operations and meeting business requirements. As a result, companies are emerging to capitalize on this trend, largely focusing on building operational infrastructure for these/LLM models.
Rather than hastily following the hype/trend, we have conducted thorough research and developed the most responsible ways to safeguard LLMs. We are collaborating with industry pioneers like Neobank bunq and AI-based Anti Money Laundering tool (AML) Strise to apply our research on real-world use-cases of LLMs in fintech and other high-risk industries.
This article outlines our research approach and shares our findings on LLM explainability, guardrails, and operations, providing a glimpse of our upcoming platform features.
LLMOps vs. MLOps: Understanding the Greater Challenges in Large Language Model Operations
It is important to consider what makes (open-source) LLMs different from other machine learning (ML) models when it comes to putting them into production (MLOps) and doing so responsibly. Together with our research partners, we have identified the main challenges companies face when putting LLMs in production, which resulted in the following 7-point list.
Some of these challenges are easily solved by deploying the LLMs on Deeploy. For the remaining challenges, Deeploy has researched and developed novel features and methods, making Deeploy completely compatible with LLMOps.
In this article we will walk you through the list of the 7 biggest challenges, diving into LLM interpretability and explainability, and illustrating the solutions we found. If you want a quick glance, the list is summarized in the LLMOps Challenges Cheat Sheet:
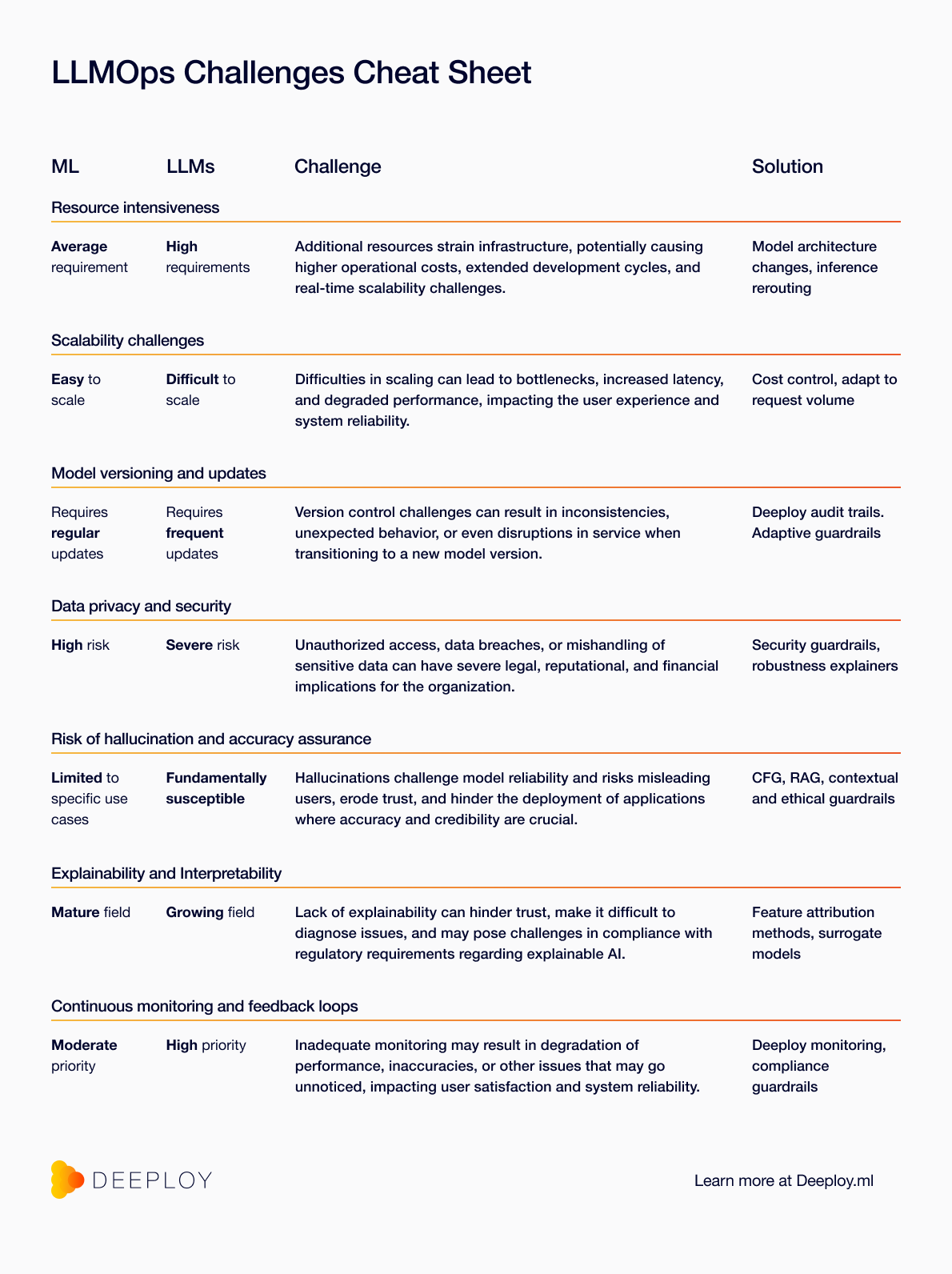
1. Resource Intensiveness:
LLMs are more resource-intensive than regular ML in terms of computation, memory, and storage during both training and inference due to their size and complexity. This places a significant strain on infrastructure, potentially leading to high operational costs, longer development cycles, and challenges in scaling for real-time or high-throughput applications. Responsible allocation and utilization of resources are critical to balance efficiency with environmental and economic sustainability.
Solution: There are many new developments that serve to make LLMs less computationally heavy, such as reduced numerical precision (quantization), the use of more memory-efficient attention algorithms (flash attention), and methods to reroute requests to different-sized LLMs. Deeploy can support models of any size and also supports the deployment of middleware that can reroute requests to different models if you want to optimize for cost efficiency. Resource intensiveness of current LLMs remains one of the main unsolved challenges that make evaluating the ROI of your use case important.
2. Scalability Challenges:
Scaling LLMs horizontally or vertically is more complex than scaling regular ML due to their size and computational demands, making deployment and real-time usage challenging. Difficulties in scaling can lead to bottlenecks, increased latency, and degraded performance, impacting the user experience and system reliability.
Solution: Smart allocation of resources. Deeploy enables smart ways to allocate resources by assigning (GPU) nodes to models only when required based on request load while being managed by cost controls.
3. Model Versioning and Updates:
LLMs may undergo more updates or improvements than regular ML, for example, due to finetuning and adaptation to different contexts and domains, requiring careful versioning and management to ensure consistent performance and behavior across deployments. Version control challenges can result in inconsistencies, unexpected behavior, or even disruptions in service when transitioning to a new model version.
Solution: Update based on Git versioning. Deeploy is tightly coupled with Git versioning. Not only does this mean that the code is versioned, but a Git repository is the source of truth for model metadata such as training data and model properties. This allows Deeploy to enable robust audit trails that make it possible to trace and reproduce every change, prediction, explanation, and deployment. Deeploy also ensures clear ownership of deployments and workspaces so that responsibility can be easily allocated for model updates and versions.
To enable model updates at the right time, Deeploy supports the application of adaptive guardrails for LLMs. In the world of fintech, an adaptive framework is for example vital for LLMs used in fraud detection. As fraud techniques continually evolve, the LLM should adapt to recognize new patterns and risks. This adaptive approach not only maintains alignment with ethical and legal standards but also identifies novel fraud attempts to protect customers and the organization. The adaptive framework can hence be used to ensure that the model gets updated to a new version as the application environment changes.
4. Data Privacy and Security:
LLMs might handle more unstructured data than regular ML which opens data privacy risks, especially if the LLM is fine-tuned on sensitive data and the data is not handled and stored securely. Unauthorized access, data breaches, or mishandling of sensitive data can have severe legal, reputational, and financial implications for the organization.
Solution: Deeploy supports the application of security guardrails to ensure data privacy and model safety. Considering the sensitive financial data that fintech companies and other regulated markets handle, security safeguards are of paramount importance. They prevent the model from being manipulated to disclose confidential customer account information and ensure the model remains resilient against external hacking attempts. The goal is to protect sensitive financial information and maintain trust. Deeploy also supports explainability methods that test for model safety which means that the model robustness can be tracked in terms of security metrics, for example by using the Adversarial Robustness Toolbox (ART) library.
5. Risk of Hallucination and Bias:
LLMs, as generative models, are at risk of generating hallucinations, wherein they may produce text that is not factual or contextually accurate. This is generally not an issue with regular ML or reduced to a few NLP models. Hallucinations pose a significant challenge in ensuring the model consistently produces correct and reliable information. LLMs can also be subject to bias that arises from the fact that these models learn from vast amounts of text data, which can contain inherent biases, leading the LLMs to produce or reinforce biased or unfair content in their outputs. These inaccuracies and biases can mislead users, erode trust, reinforce prejudices, and create ethical concerns that hinder the deployment of LLMs in applications where accuracy and credibility are crucial.
Solution: These problems can be solved in different ways during model development, for example by utilizing different techniques such as Classifier Free Guidance (CFG) during inference to make the model adhere more strictly to the prompt. Another method is to give better data to the LLMs, for example through the use of Retrieval Augmented Generation (RAG), ensuring that the data used for the models come from trusted sources. Deeploy enables the user to connect their databases to their models, making RAG a possibility with Deeploy.
Deeploy also supports the deployment of appropriate guardrails. Fintech firms often employ LLMs in customer support through chatbots. In this context, contextual guardrails are essential to fine-tune the model’s behavior and ensure accurate behavior. Such contextual guardrails ensure that the model maintains professionalism and appropriateness in its tone.
It is also possible to deploy ethical guardrails. Imagine a scenario where an LLM is employed to provide personalized investment advice to clients. Ethical boundaries are crucial here to prevent the model from recommending high-risk investments without proper disclosure. This ensures that recommendations align with the client’s best interests and adhere to ethical guidelines.
6. Explainability and Interpretability:
Understanding the decision-making process of LLMs can be challenging due to their complex and opaque nature. Lack of explainability can hinder trust, make it difficult to diagnose issues, and may pose challenges in compliance with regulatory requirements regarding explainable AI.
Solution: As experts in eXplainable AI (XAI), we at Deeploy have been working hard on developing explainability methods for LLMs that can support the model developers in performing quality assurance of model output and for debugging purposes. These are our findings and developments in this field:
Feature attribution methods
This includes both local and global explanations of model behavior. Local explanations focus on understanding a model’s predictions for a specific instance, while global explanations aim to provide insights into the model’s overall behavior across the entire dataset. One way of interpreting models is to try to answer the why-question: why did the model predict a certain output? The why-question is commonly answered with attribution methods that qualify the importance of the input given a model’s inner processing and final prediction. There have been many exciting developments in the industry to create feature attributions for LLMs. Together with Bunq we have tested and implemented feature attribution methods for LLMs that use gradients (showing how much a parameter is contributing towards the prediction), perturbations (estimating importance of inputs by introducing noise, which can be used to determine the importance of layers in the model), and attention weights (by themselves or multiplied by other quantifies as an indication of feature importance). These methods are showing promising results and we have also developed new ways of visualizing the results intuitively, making sure the feature attribution explanations are actionable for the model developers.
Explainable surrogate models
Based on cutting-edge research in LLM explainability, we have also developed an approach that can be used specifically for classification use cases that can detect model uncertainty and provide additional information on why the model is unsure based on internal reasoning. This approach involved the building of a classifier model on top of the LLM which can then be used to explain the model output using common explanation methods like SHAP. This makes use of a surrogate model to explain the more complex LLM model and has been tested on several benchmark datasets with good results. Surrogate models can also be used to detect possible hallucinations, and hence can also be implemented as a guardrail.
Adapting explanations to target audience
One significant aspect of our collaboration with Strise involves understanding and catering to the specific needs of various stakeholders involved in LLM deployments. We recognize that industry experts, compliance officers, data scientists, and end users have different levels of expertise and understanding of LLMs. For instance, compliance officers and end users may not find heat map visualizations of attention mechanisms meaningful. For that reason, we have made a prototype of a natural language explainer that leverages the capabilities of LLMs to translate common feature attribution methods into human-understandable explanations. This model is fine-tuned to create explanations of particular granularities, making use of some core understanding of explainability that states that good explanations should be contrastive, selected, devoid of statistics, and adapted to the target audience.
The difficulty of model agnostic explainability
For now, explainability methods that are model agnostic remain difficult, as many of the current explainability techniques for LLMs rely on access to the model internals. However, Deeploy is continuously researching model-agnostic approaches and staying up to date with the work of the academy meaning any future model-agnostic explainability method is expected to be on our platform.
7. Continual Monitoring and Feedback Loops:
Ongoing monitoring and feedback loops are essential to ensure LLMs’ performance, adaptability, and alignment with business objectives and regulations, especially considering their potential long-term use in various applications like chatbots, content generation, and more. Inadequate monitoring may result in degradation of performance, inaccuracies, or other issues that may go unnoticed, impacting user satisfaction, compliance with regulation, and system reliability.
Solution: Deeploy as a platform already enables effective monitoring of models, predictions, and interactions. This includes model drift, bias detection, and performance metrics. With Deeploy it is easy to define custom alerts to metrics and to easily discover root causes of model degradation. The deployed guardrails of LLMs can easily be monitored for their effectiveness. Deeploy also ensures compliance with regulation, through customization of compliance checklists, and through the possibility of deployment of regulatory compliance guardrails. Fintech companies often use LLMs to generate automated responses to customer queries, particularly those related to financial regulations and compliance. Compliance guardrails are essential to ensure that the model’s responses remain up-to-date with the latest regulatory changes, such as anti-money laundering (AML) laws. This not only helps avoid legal issues but also safeguards customer data and helps build trust in the company.
Advancing Responsible AI: Our Commitment to LLMOps
At Deeploy we recognize that LLMs are not going anywhere in the foreseeable future and as a leader in the Responsible AI field, we are making it a priority to ensure that these models are handled responsibly. We are therefore continuously following and leading the research and development of explainability and guardrails of LLMs to bring the necessary features that ensure responsible LLM deployment into our platform.
If you want to work with us on LLM explainability and guardrails: reach out and we are happy to discuss further how we can best help each other!